
A Brief Exploration of Pixel Flow Level Intensity
How can we model level intensity in Hybrid-Casual puzzle games?

The huge success of Pixel Flow! by Loom Games seems to have influenced the entire market. It looks like we’ll keep seeing games built around a similar format for a while. Ignoring such a popular title would feel unfair, so it’s worth taking a brief look at it.
In this post, I’ll focus on a slightly more mechanical aspect of the game and briefly discuss how we might estimate the intensity of levels while designing them. The main goal is to show how we can help level designers while preparing levels by giving such feedback.
Before getting started, I’d like to share the chart that I will present at the end of the post right away. Below you can see how level intensity values, scored on a scale from 1 to 10, are distributed across the first 50 levels.
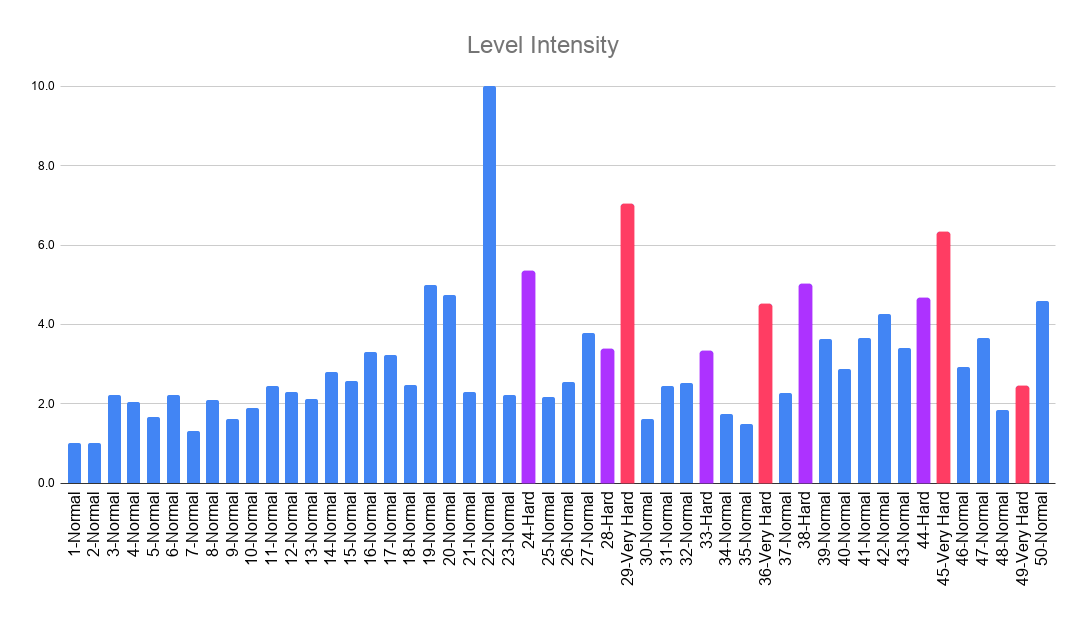
Level intensity is treated as a measure of the stress required to complete a level. This stress may be caused by difficulty, or the board design may force players to make more moves.
Before moving on to the calculations, let’s briefly talk about the assumptions:
I tried to estimate the level intensity by dividing the player’s total number of moves by the number of shooters. I assume that if the number of clicks on a shooter block increases, level intensity increases because the player may try to avoid failing (although counterexamples are also possible, which is why intensity itself cannot explain level difficulty alone).
I assumed the dataset I use represents a player segment (but in reality, we would need real player data).
I assumed no booster use, so the data was selected based on this.
In reality, we would need more levels for a good analysis. However, recording the data takes too much time, so looking at 50 levels is enough to discuss the methodology.
You can find the dataset sources I used here:
I recorded the number of moves, the average counter number per shooter and the number of shooters from this YouTube playlist.
I retrieved the number of waiting lines and the number of colors from the Pixel Flow deconstruction prepared by Yagiz Gur.
Now that I’ve briefly outlined the assumptions, we can return to the main goal of this post: can we model how intense our levels are for our own games as well?
We discussed a more ML-focused version of this idea in the paper Balancing Level Difficulty in Hybrid-Casual Puzzles using ML and System Modeling. I highly recommend taking a look at it.
First, let’s take a look at how the game mechanics relate to level intensity. As usual, we will try to apply white-box modeling:
Increasing the number of colors may increase the number of moves. Because the slots may fill up faster if the player cannot select the shooters in the correct order.
Increasing the average counter number per shooter may increase the number of moves. Because higher counter numbers mean additional loops around the board.
Increasing the number of shooters may increase the number of moves. Because they may accumulate in the slots while playing a longer level.
Increasing the number of waiting lines may decrease the number of moves. Because the player will have more choices to select from.
Normally, we should also consider obstacles, which I discussed earlier in the article I mentioned before. However, I won’t include them here because we don’t need that complexity in this short post.
So, basically, extra moves should be proportional to the following equation:
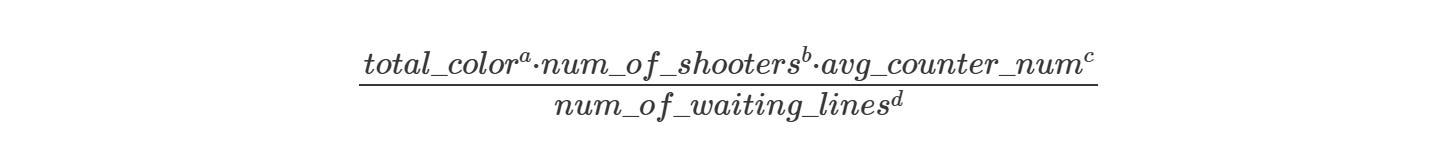
The reason I use the values a, b, c, and d as exponents rather than as multipliers is that it allows us to adjust the weights of the features more easily.
When I used this model in a linear regression to predict extra moves, the R² was 0.76 and the 5-fold CV R² was 0.61, with moderate errors, which is expected considering how small the dataset is.
Below, the actual and predicted level intensity values are shown after the extra move predictions, before being scaled to the 1–10 range.
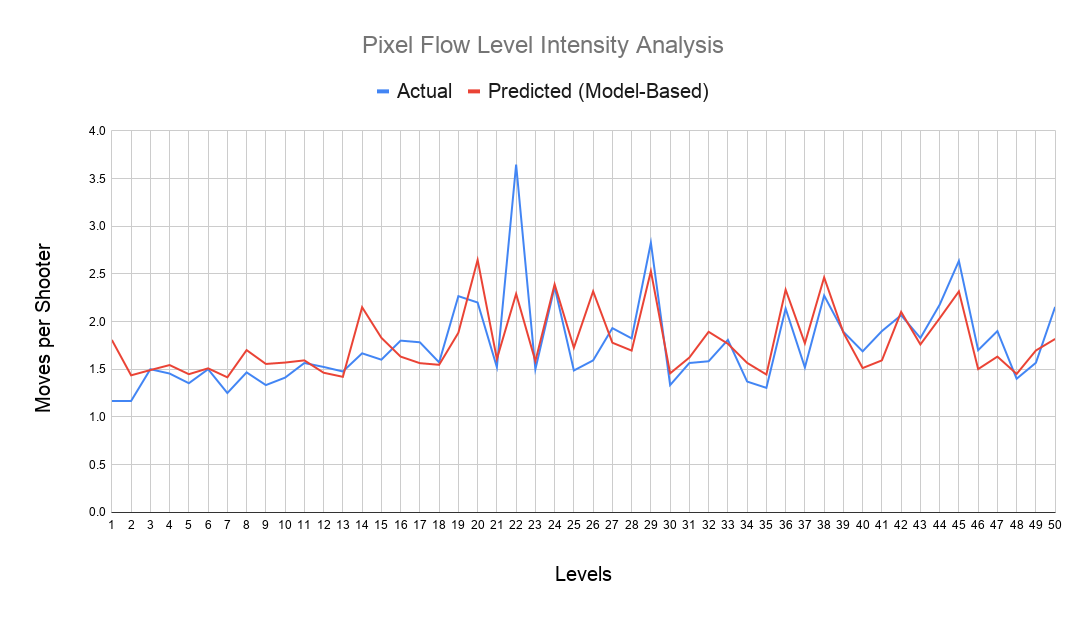
It’s actually quite useful in terms of giving level designers insight, especially when new levels start to be added to the existing level set. It also seems possible to roughly estimate the intensity of levels that haven’t been released yet.
To be honest, I really wonder how it would look with a bigger dataset!
This post ended up being quite short, but it was still nice to do a bit of brainstorming.
I also recommend reading my other posts where I discuss why we should build level design systems that are more reasoning-driven and predictable, rather than relying on black-box level design.
See you next time!